The EURO-NMD registry hub for all neuromuscular diseases, including undiagnosed patients, will be a FAIR registry where Interoperability and FAIRification will be realised. This means that it should be possible for health records written in different languages, formats and stored in different registries to be combined, achieving interoperability. In the project where the EURO-NMD is being built, we will demonstrate how it can be interoperable with four existing patient registries: CRAMP, DMScope, Duchenne Data Platform and SMArtCARE.
The term ‘FAIRification’ is used to describe the process of making a data source Findable, Accessible, Interoperable and Reusable. Many stakeholders are involved in this process, each bringing different levels of expertise. The starting point is a generic step-by-step workflow [1] that is divided in three ‘phases’: Pre-FAIRification, FAIRification and Post-FAIRification (Figure 1). Before discussing the latest developments with interoperability and FAIRification activities for EURO-NMD, it would be useful to describe first the pathway for implementing a FAIR ERN Registry.
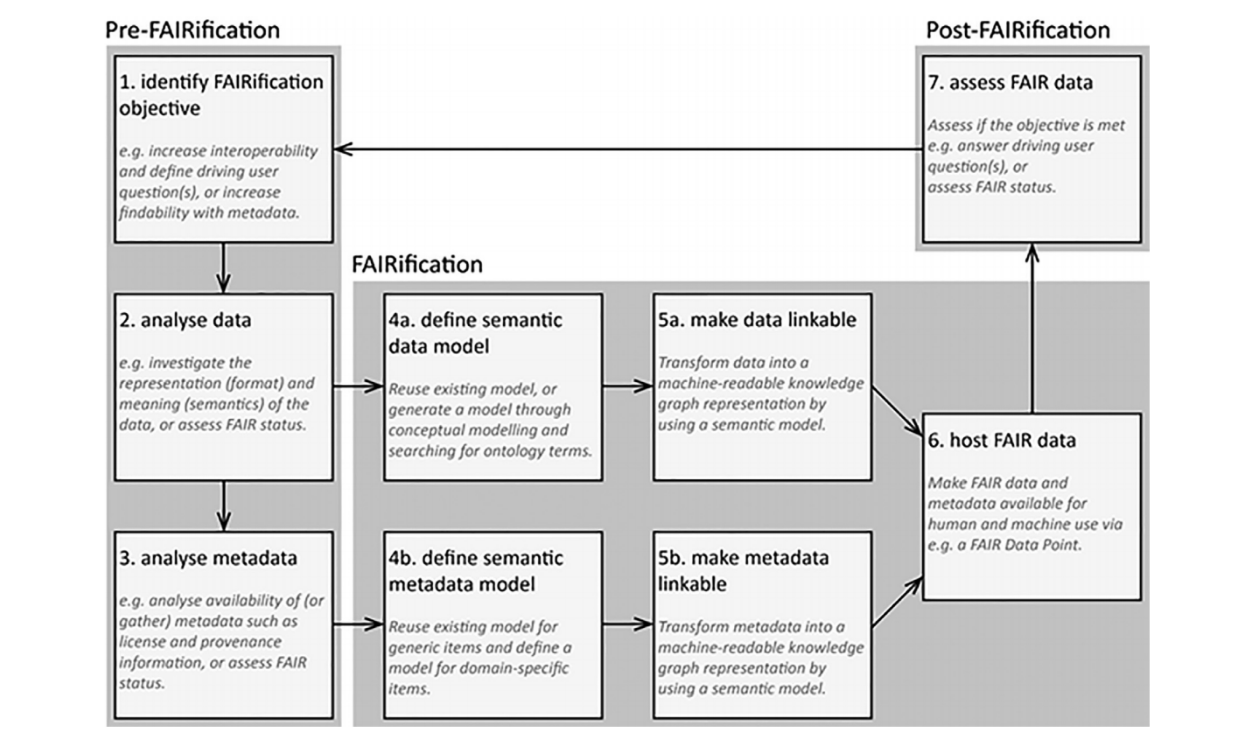
Figure 1: A generic step-by-step workflow for the process of making data FAIR (‘FAIRification’) Jacobson et al., 2019
Pathway for implementing FAIR
Following the FAIR principles, allow EURO-NMD to answer questions such as: “What is the incidence of Duchenne Muscular Dystrophy across Europe.” This will be achieved through federated querying enabled through the virtual platform of EJP RD. The EURO-NMD registry hub will only contain a subset of patients and a subset of data elements. For more comprehensive searches, queries will be sent across all NMD registries (possibly via the EURO-NMD registry hub) or go to registries with more specific information and all that from one place, the virtual platform!
FAIR data principles [2] encourage robust management of data and metadata (i.e. data about data) for efficient use and reuse by humans and computers. They are intended to support querying and analyzing of data stored in different resources to answer specific questions by different stakeholders.
The virtual platform, currently in development, will offer a graphical user interface (GUI) for humans and an Application Programming Interface (API) for computers to query data across existing registries and the registry hub. However, this can only be possible when the data exposed by various registries are FAIR (Findable, Accessible, Interoperable and Reusable):
Findable
The ‘F’ of Findable means that the FAIR registry should be well described. That all the metadata about the data that is contained in the registry should be visible and registered in a directory of registries such as the European Rare Diseases Registry Infrastructure (ERDRI) [3] also known as the ‘registry of registries’ where all the metadata about the registries are being collected and catalogued.
Accessible
Access procedures for the ‘A’ of FAIR need to be well-defined. For that, data use policies should also be machine readable. Hence, terms from Data Use Ontology (DUO) are used which say what can be done with what data elements, under appropriate approval from the Medical and Ethical Committee, in-line with informed consent given by patients and following GDPR. Another mechanism for access is the Authentication and Authorization Interface (AAI) that should be implemented at a European level, noting that ‘accessible’ does not equal ‘open’.
Interoperable
The ‘I’ of FAIR is the most challenging facet. Interoperability between resources requires the use of specific elements, tools and machine-readable formats:
- Common Data Elements defined by the European Commission [4] are used to form the minimum Common Data Elements (CDEs) that should be collected by all ERNs registries currently in development.
- Ontologies are needed: these are standard codes of elements collected in databases such as the Human Phenotype Ontology (HPO) [5].
- Semantic model [6] is used which defines the meaning and relations between those elements collected in databases. The semantic model has been developed with several stakeholders in the rare disease community. There is now a continuously revised and updated semantic model for the CDEs that need to be collected by the ERNs. It contains relationships between different elements such as those related to a subject (i.e. age and gender) and diagnosis – all supported by the relevant ontologies such as the Human Phenotype Ontology for diagnosis.
- FAIR Data Point [7] (FDP) is a software that allows data owners to expose metadata and data in a FAIR manner. It takes care of a lot of the issues that need to be addressed to make data FAIR: It stores the metadata for Findability and Reusability. It offers access protocols (Authentication & Authorisation procedures). It addresses the Interoperability of the metadata it stores, but it leaves the Interoperability aspects for the data itself to the data provider.
- SPARQL is the language used for querying through the use of FDPs.
Reusable
In order to be reusable, the ‘R’ of FAIR, data should be accessed in such a way that computers need to make sense of it. For this purpose, Resource Description Framework (RDF) is used as an exchange language between these different registries.
Citations
[1] Jacobsen A, Kaliyaperumal R, da Silva Santos LOB, Mons B, Roos M and Thompson M. A Generic Workflow for the Data FAIRification Process. Data Intelligence. 2020; Doi: 10.1162/dint_a_00028
[2] Wilkinson MD, Dumontier M, Aalbersberg IJ, Appleton G, Axton M, Baak A, et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data. 2016; Doi: 10.1038/sdata.2016.18
[3] European Commission, European Rare Disease Registry Infrastructure (ERDRI), European Commission.
[5] The Human Phenotype Ontology.
[6] Semantic data model of the set of common data elements for rare disease registration, LUMC.